Videos
TOSSI · MEDIA
Videos
Recordings, demos, and walkthroughs from the TOSSI project — end-to-end Open RAN interoperability, testing at scale, and GPU acceleration.
 GPU Offload4:32
GPU Offload4:32Building the AI-RAN Data Path in OCUDU: Inline GPU Processing for PRACH and SRS
Inline GPU acceleration in OCUDU Open RAN using NVIDIA GPUDirect RDMA. Fronthaul packets are delivered directly from the NIC into GPU memory where PRACH detection and SRS channel estimation execute inline — no CPU copy. Shows 3.3× speedup for PRACH (106 µs vs 352 µs) and sub-linear SRS scaling up to 256 UEs.
 Integration18:42Jun 21, 2026OAI L1 + xFAPI + OCUDU DU-High | End-to-End Open RAN InteroperabilityEnd-to-end Open RAN interoperability across the FAPI split. OAI L1 (nFAPI PNF) talks to OCUDU DU-High through the xFAPI bridge in OAI_OCUDU mode — nFAPI over P5 SCTP and P7 UDP between hosts, then xSM shared-memory transport into the OCUDU MAC scheduler. Demonstrates a two-host deployment with F1AP up to the CU.
Integration18:42Jun 21, 2026OAI L1 + xFAPI + OCUDU DU-High | End-to-End Open RAN InteroperabilityEnd-to-end Open RAN interoperability across the FAPI split. OAI L1 (nFAPI PNF) talks to OCUDU DU-High through the xFAPI bridge in OAI_OCUDU mode — nFAPI over P5 SCTP and P7 UDP between hosts, then xSM shared-memory transport into the OCUDU MAC scheduler. Demonstrates a two-host deployment with F1AP up to the CU.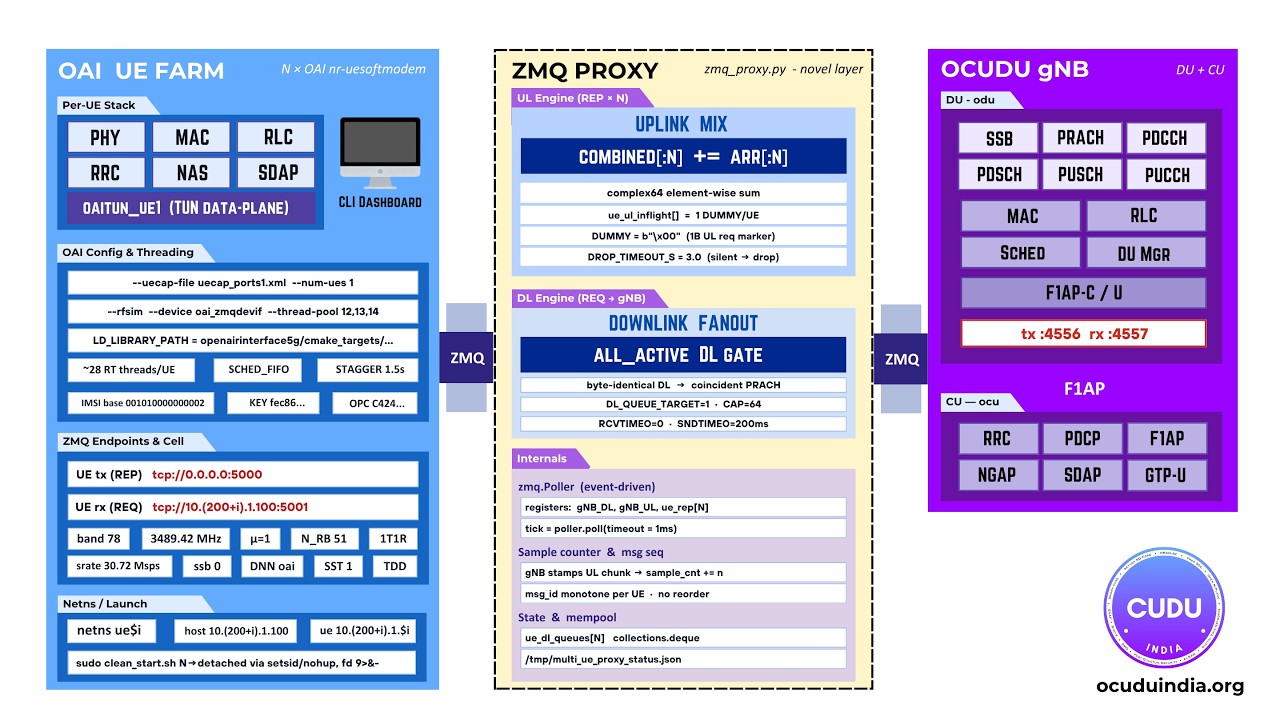 Testing24:10May 25, 2026Scaling RAN Testing: From Single UE to Multi-UE SimulationScaling open RAN testing from a single UE to a multi-UE simulation. Walks through the OAI ZMQ-capable nr-uesoftmodem, a Python IQ-superposition proxy that fans the downlink and sums uplinks for N UEs, per-UE Linux network namespaces, wave admission into the 5G core, and a live dashboard driving the demo.
Testing24:10May 25, 2026Scaling RAN Testing: From Single UE to Multi-UE SimulationScaling open RAN testing from a single UE to a multi-UE simulation. Walks through the OAI ZMQ-capable nr-uesoftmodem, a Python IQ-superposition proxy that fans the downlink and sums uplinks for N UEs, per-UE Linux network namespaces, wave admission into the 5G core, and a live dashboard driving the demo.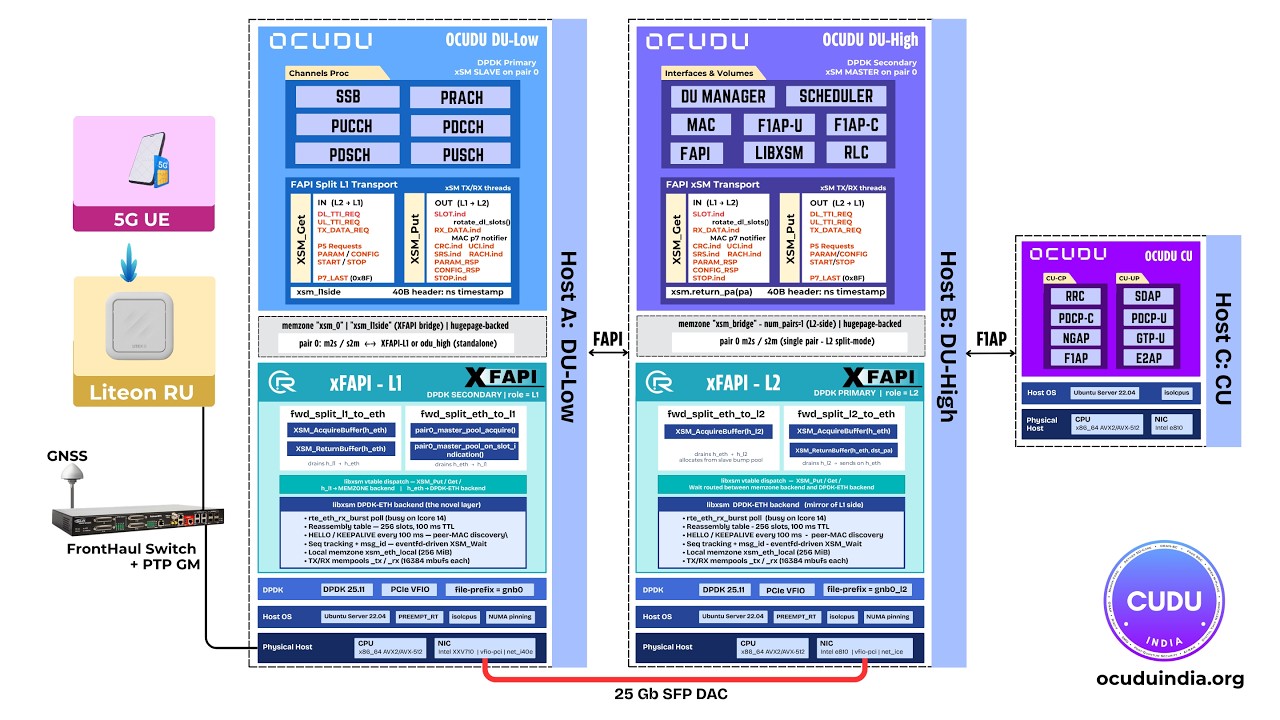 Integration12:35May 19, 2026xFAPI Demo: Disaggregated FAPI Interface in Open RANA disaggregated FAPI interface in open RAN. Walks through the latest xFAPI release: interoperable deployment of L1 and L2 through a modular FAPI-based architecture and an xSM shared-memory transport.
Integration12:35May 19, 2026xFAPI Demo: Disaggregated FAPI Interface in Open RANA disaggregated FAPI interface in open RAN. Walks through the latest xFAPI release: interoperable deployment of L1 and L2 through a modular FAPI-based architecture and an xSM shared-memory transport. GPU Offload15:08May 3, 2026GPU Offloading of PRACH Detection Using CUDA GraphsGPU offloading of PRACH detection using CUDA graphs. Walks through NVIDIA GPU acceleration for PRACH preamble detection in the upper-PHY via cuFFTDx and CUDA-graph capture, with A/B performance results measured on live 5G cells against both Split 8 and Split 7.2 radios.
GPU Offload15:08May 3, 2026GPU Offloading of PRACH Detection Using CUDA GraphsGPU offloading of PRACH detection using CUDA graphs. Walks through NVIDIA GPU acceleration for PRACH preamble detection in the upper-PHY via cuFFTDx and CUDA-graph capture, with A/B performance results measured on live 5G cells against both Split 8 and Split 7.2 radios.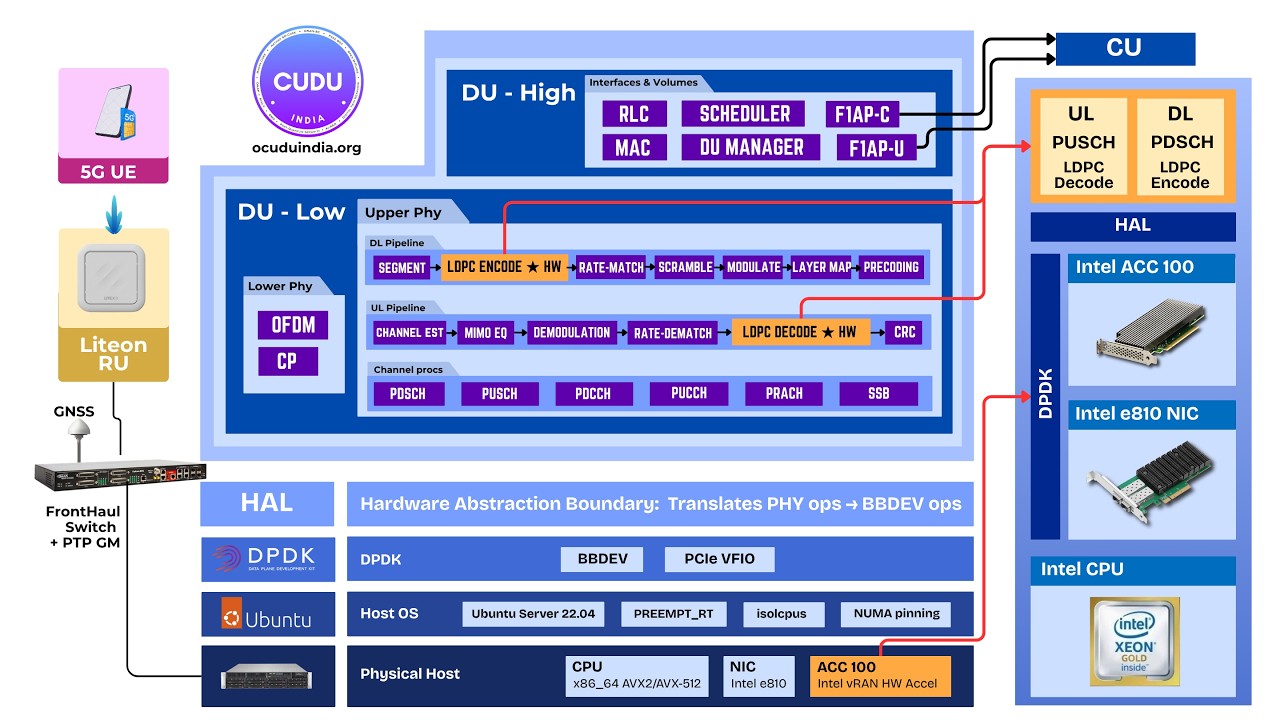 GPU Offload19:53Apr 26, 2026Offloading LDPC in PDSCH and PUSCH to AcceleratorsOffloading LDPC in PDSCH and PUSCH to hardware accelerators. Walks through the integration of accelerator cards (demonstrated on Intel ACC100) for LDPC offload into the upper-PHY via DPDK BBDEV, with A/B performance results on a live 100 MHz TDD cell against a real UE.
GPU Offload19:53Apr 26, 2026Offloading LDPC in PDSCH and PUSCH to AcceleratorsOffloading LDPC in PDSCH and PUSCH to hardware accelerators. Walks through the integration of accelerator cards (demonstrated on Intel ACC100) for LDPC offload into the upper-PHY via DPDK BBDEV, with A/B performance results on a live 100 MHz TDD cell against a real UE.