Blog
TOSSI · JOURNAL
Blog
Announcements, release notes, and project updates from TOSSI — the open, vendor-neutral RAN integration project.
 Releases
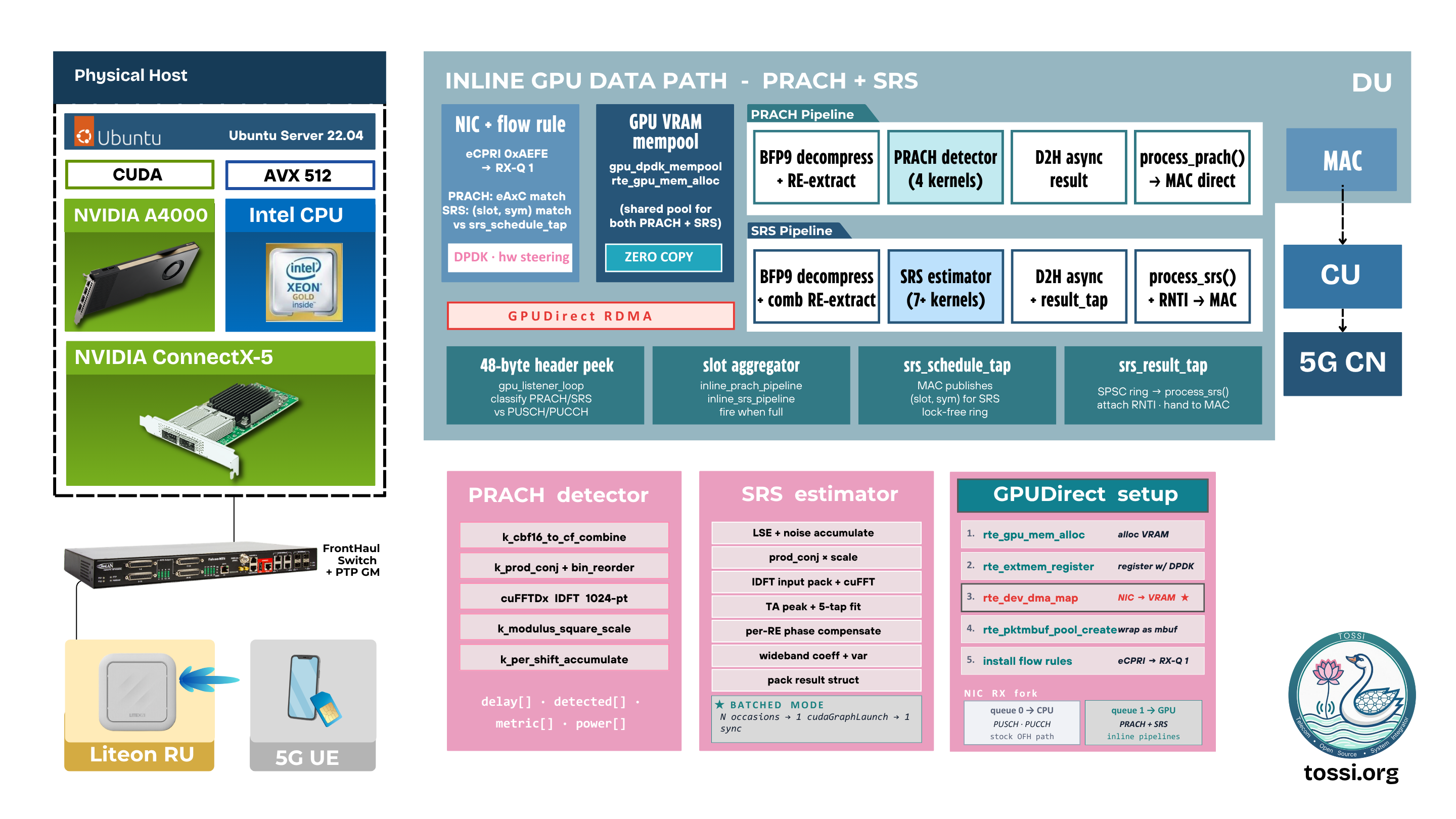
ReleasesBuilding the AI-RAN Data Path in OCUDU: Inline GPU Processing for PRACH and SRS
NVIDIA GPUDirect RDMA delivers fronthaul packets directly into GPU memory — no host copies, no PCIe bottleneck. PRACH detection latency drops 70%, SRS achieves 20× acceleration at 256 UEs, all on a workstation-class RTX A4000.
 Bridging Open RAN Ecosystems: OAI L1 with OCUDU L2 via xFAPIOAI Layer 1 (v2.4) and OCUDU Layer 2 (v26.04) interoperate through xFAPI Release 2.2 with no source changes to either project. All the integration logic lives inside xFAPI, validating Open RAN's core promise: independently developed components working together while preserving their native implementations.Read more →
Bridging Open RAN Ecosystems: OAI L1 with OCUDU L2 via xFAPIOAI Layer 1 (v2.4) and OCUDU Layer 2 (v26.04) interoperate through xFAPI Release 2.2 with no source changes to either project. All the integration logic lives inside xFAPI, validating Open RAN's core promise: independently developed components working together while preserving their native implementations.Read more →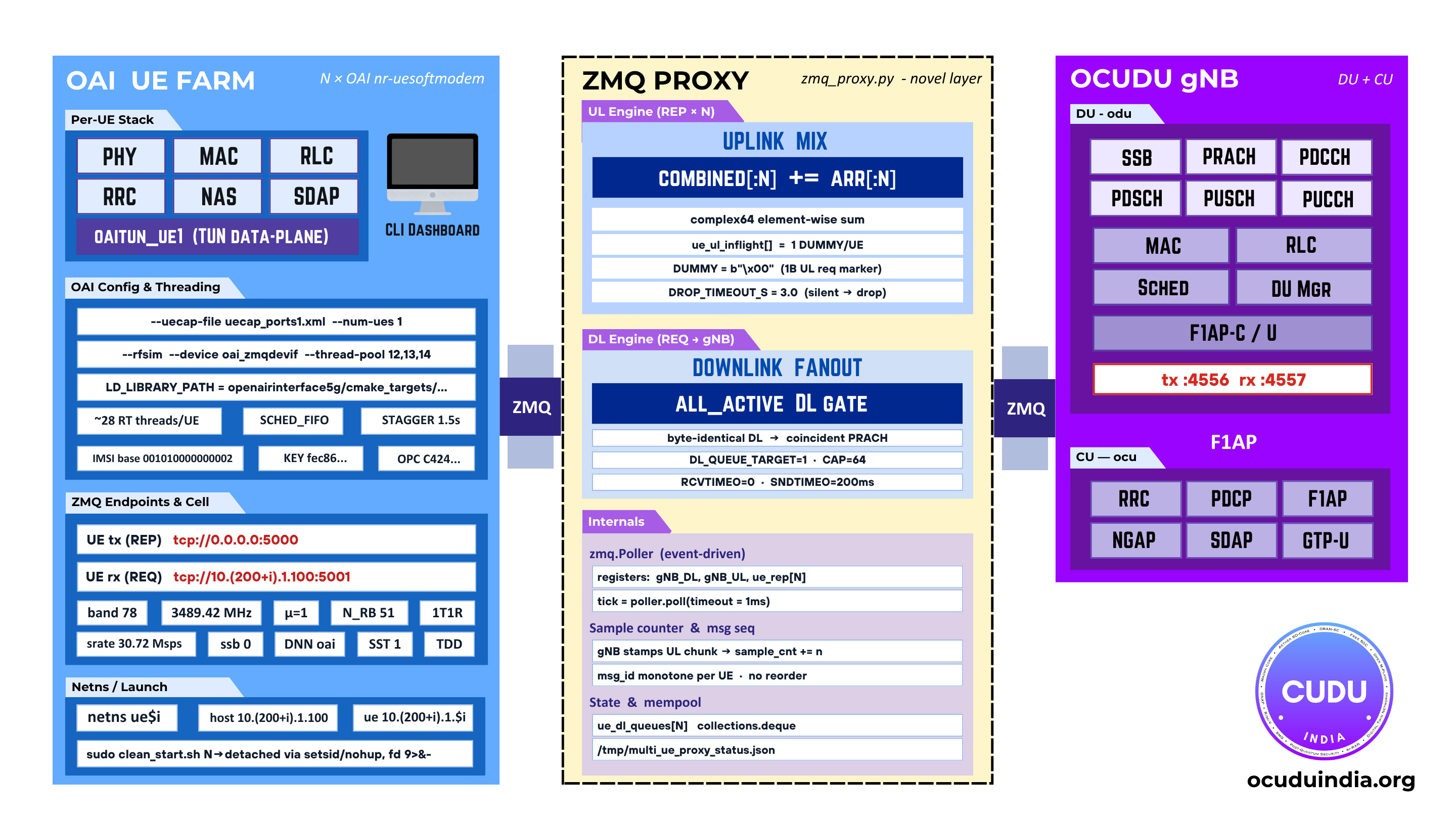 Scaling RAN Testing: From Single UE to Multi-UE SimulationOCUDU India extends OAI's new ZMQ-capable nr-uesoftmodem into a multi-UE testbed: N OAI UEs against a single OCUDU gNB, joined by a Python IQ-superposition proxy, per-UE Linux network namespaces, wave admission into the 5G CN, and a live Rust/ratatui dashboard.Read more →
Scaling RAN Testing: From Single UE to Multi-UE SimulationOCUDU India extends OAI's new ZMQ-capable nr-uesoftmodem into a multi-UE testbed: N OAI UEs against a single OCUDU gNB, joined by a Python IQ-superposition proxy, per-UE Linux network namespaces, wave admission into the 5G CN, and a live Rust/ratatui dashboard.Read more →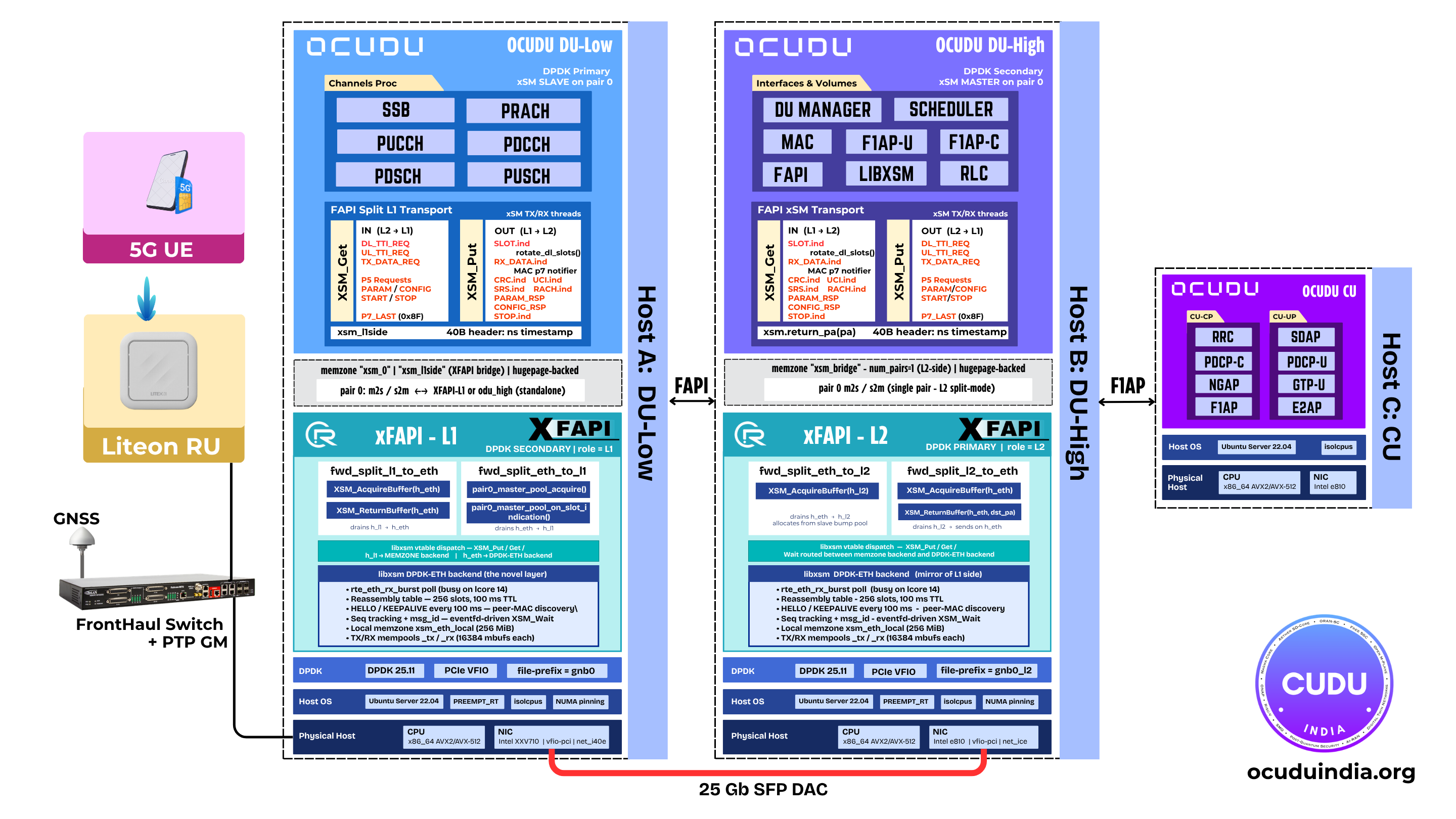 xFAPI: A FAPI L1/L2 Split for Open, Vendor-Neutral AI-RANOCUDU moves from a monolithic gNB to a fully operational FAPI L1/L2 split: odu_high and odu_low run as independent processes across the Small Cell Forum FAPI boundary, bridged by coRAN LABS' xFAPI translator. The boundary becomes open, portable, and vendor-neutral, a foundation for AI-RAN.Read more →
xFAPI: A FAPI L1/L2 Split for Open, Vendor-Neutral AI-RANOCUDU moves from a monolithic gNB to a fully operational FAPI L1/L2 split: odu_high and odu_low run as independent processes across the Small Cell Forum FAPI boundary, bridged by coRAN LABS' xFAPI translator. The boundary becomes open, portable, and vendor-neutral, a foundation for AI-RAN.Read more →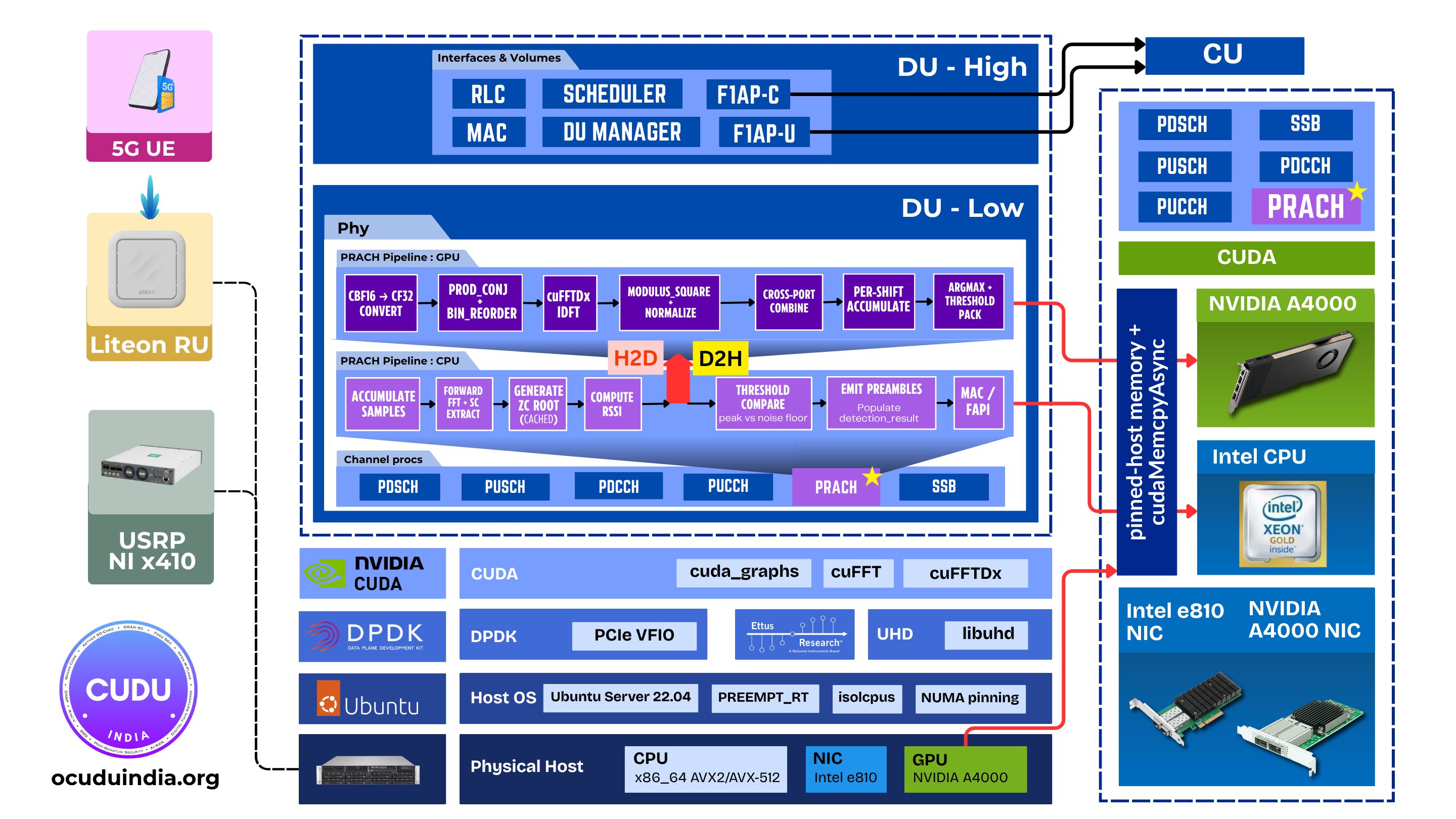 Hardware-Accelerated PRACH Detection: CUDA-Graph GPU OffloadA second hardware-acceleration path lands in OCUDU's upper-PHY: PRACH detection captured as a single CUDA graph on an NVIDIA GPU, with the IDFT running device-side via cuFFTDx. Two acceleration paths, two vendors, one binary.Read more →
Hardware-Accelerated PRACH Detection: CUDA-Graph GPU OffloadA second hardware-acceleration path lands in OCUDU's upper-PHY: PRACH detection captured as a single CUDA graph on an NVIDIA GPU, with the IDFT running device-side via cuFFTDx. Two acceleration paths, two vendors, one binary.Read more →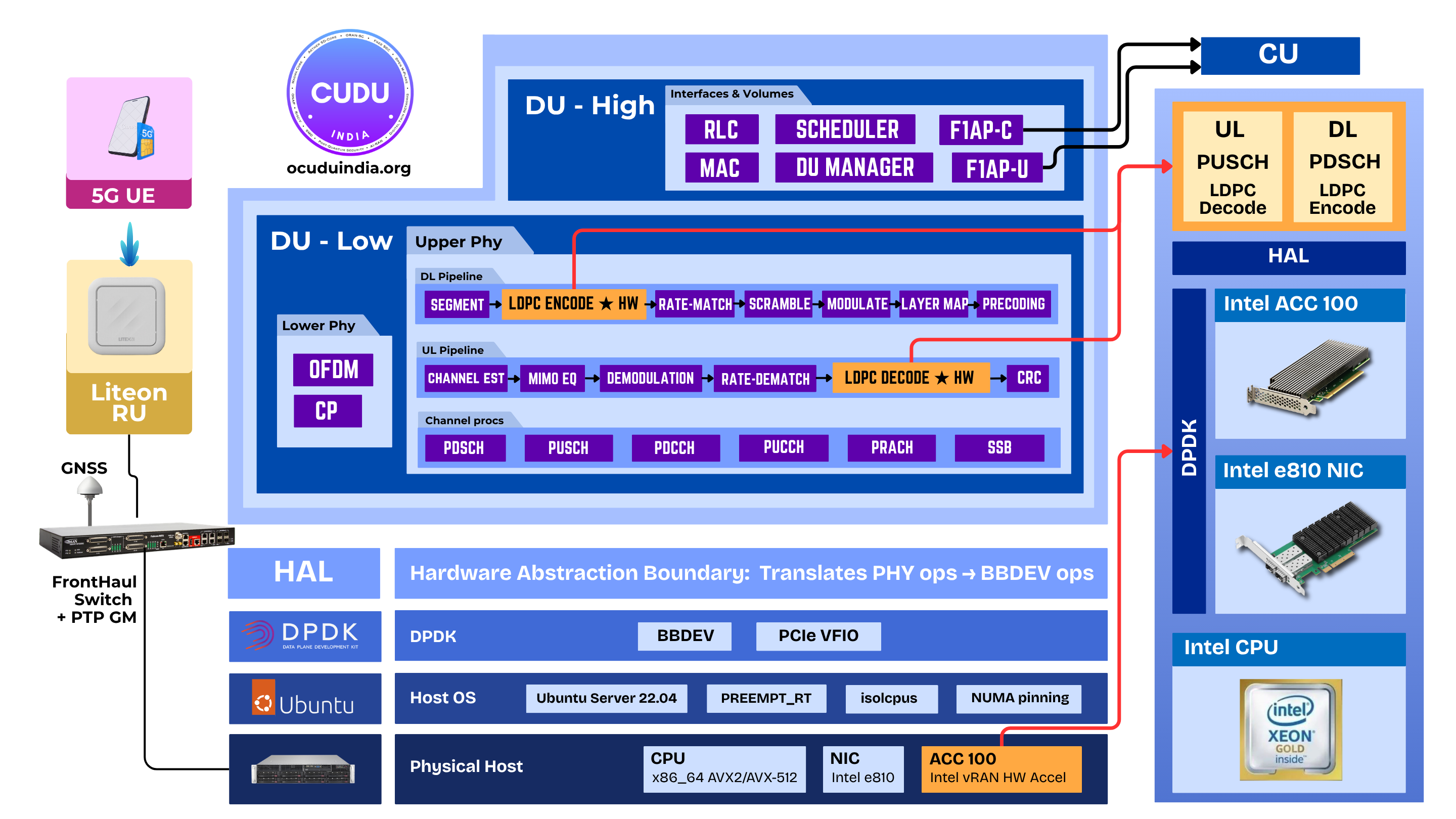 Offloading LDPC in PDSCH & PUSCH to Hardware AcceleratorsA BBDEV-based execution path for hardware-accelerated LDPC lands in OCUDU's upper-PHY, with a first reference backend on Intel ACC100 and a HAL designed to extend cleanly to next-generation accelerators.Read more →
Offloading LDPC in PDSCH & PUSCH to Hardware AcceleratorsA BBDEV-based execution path for hardware-accelerated LDPC lands in OCUDU's upper-PHY, with a first reference backend on Intel ACC100 and a HAL designed to extend cleanly to next-generation accelerators.Read more →