
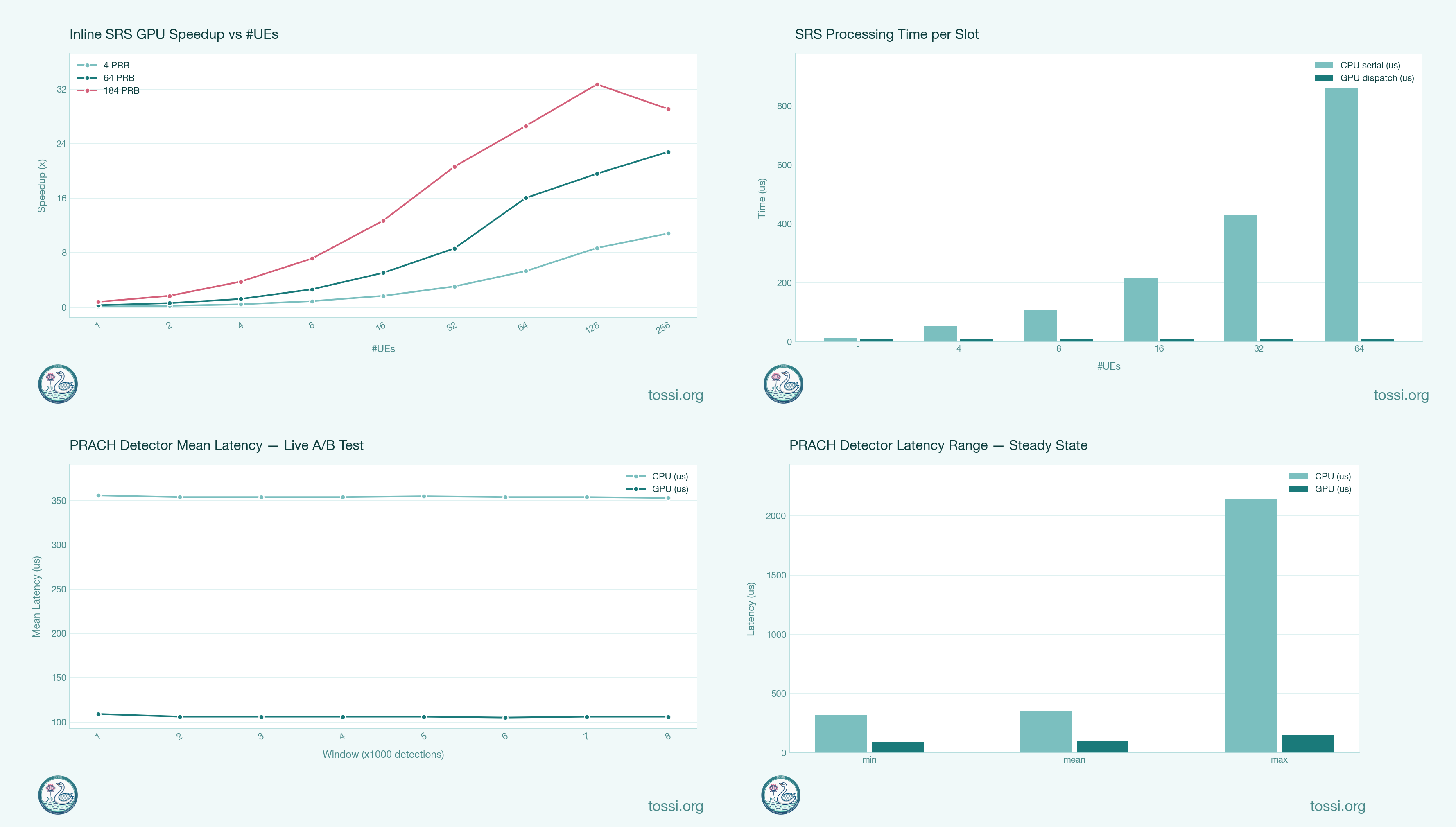
NVIDIA GPUDirect RDMA delivers fronthaul packets directly into GPU memory — no host copies, no PCIe bottleneck. PRACH detection latency drops by 70%, and SRS channel estimation achieves more than 20× acceleration at 256 UEs, all on a workstation-class RTX A4000.
As the telecommunications industry moves toward AI-RAN and heterogeneous compute architectures, accelerating Layer 1 processing is becoming increasingly important. Modern Open RAN deployments are no longer limited to CPUs alone. GPUs, hardware accelerators, and specialized processing engines are being introduced to meet growing performance demands while enabling new classes of radio intelligence.
However, many acceleration approaches still retain a significant bottleneck: data movement. Even when signal processing executes on a GPU, radio samples often travel through CPU memory before being copied across PCIe into the accelerator. Computation becomes faster, but the data path remains constrained by unnecessary memory transfers between devices.
There is also a common perception that GPU-accelerated RAN requires expensive data-center-class hardware. In practice, that assumption can become a deployment barrier of its own. AI-RAN should not be limited to organizations with access to large-scale accelerator infrastructure.
With the latest OCUDU release, we introduce a different approach. Inline GPU Acceleration for PRACH Detection and SRS Channel Estimation, powered by NVIDIA GPUDirect RDMA, enables radio data to arrive directly into GPU memory where processing begins immediately. The implementation runs on widely available workstation-class GPUs, including the NVIDIA RTX A4000, while preserving a migration path toward larger accelerator platforms as deployment requirements evolve.
At TOSSI, our vision is to enable a modular, accelerator-aware Open RAN ecosystem where compute resources can be introduced without disrupting existing architectures. This release represents another important step toward that goal.
Why the AI-RAN Data Path Matters
The future of AI-RAN is not defined solely by faster processors or larger AI models. It is defined by how efficiently radio data reaches those accelerators.
Traditional architectures introduce multiple memory copies before processing can begin. Each transfer consumes bandwidth, adds latency, and limits scalability. As more PHY functions, AI models, and advanced radio algorithms move toward accelerators, the cost of moving data increasingly outweighs the cost of computation itself.
To fully realize AI-RAN, radio data must be delivered directly to the compute platform where intelligence resides. That is precisely the problem inline GPU processing is designed to solve.
The Evolution of RAN Acceleration
The journey toward accelerator-native RAN can be viewed in three stages.
Traditional CPU Processing
In conventional Open RAN deployments, radio packets arrive in host memory and the CPU performs decompression and all PHY processing in software. While flexible, CPU-only processing becomes increasingly expensive as bandwidth, cell capacity, and user density increase.
Accelerator Offload
Previous OCUDU releases introduced hardware acceleration through Intel ACC100 for LDPC encoding and decoding, and CUDA Graph accelerated PRACH detection. These innovations significantly reduced computation time. However, radio samples still passed through CPU memory before reaching the accelerator. The accelerator performed the work; the CPU still moved the data.
Inline GPU Processing
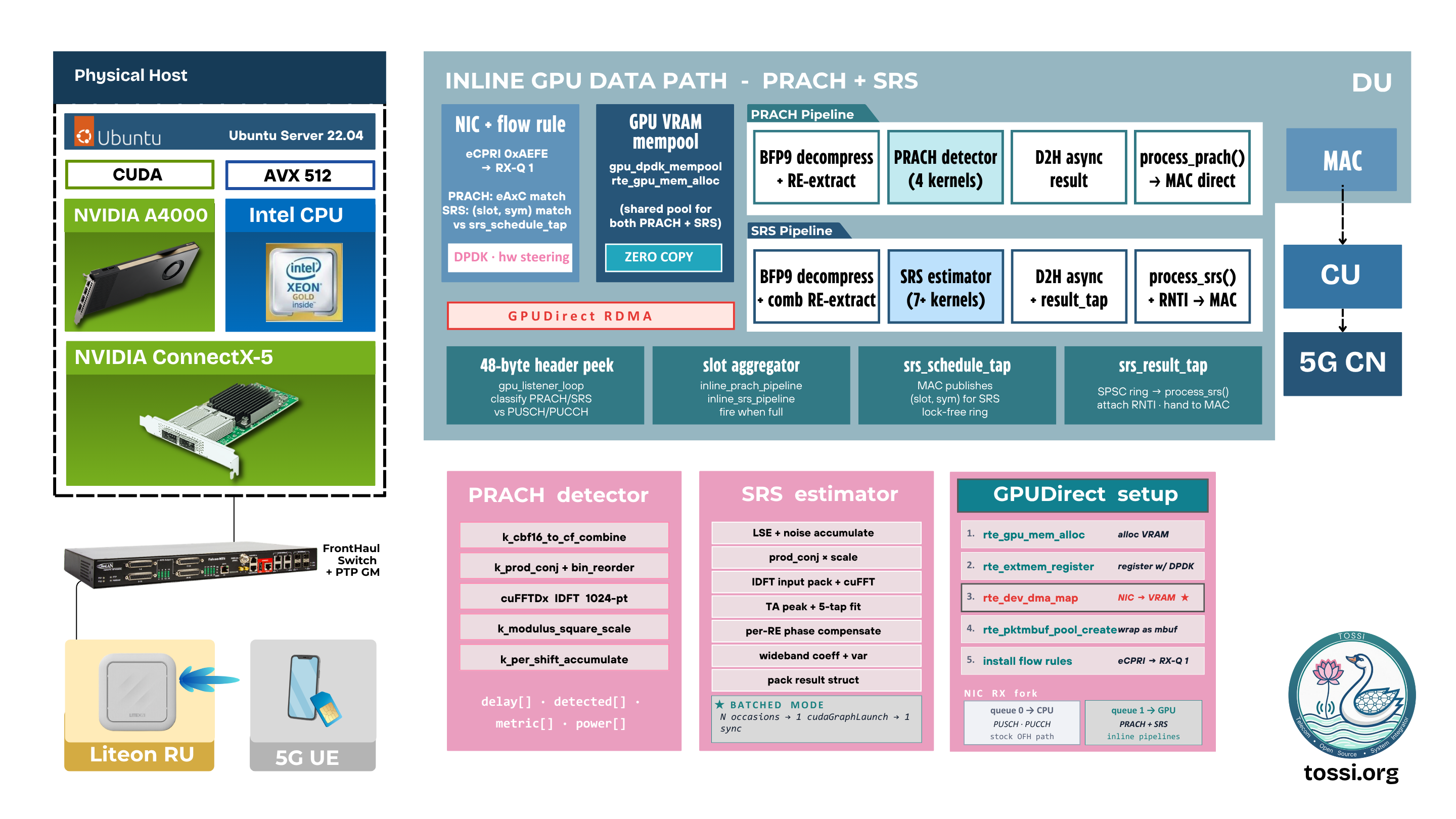
The latest release removes that dependency. Using NVIDIA GPUDirect RDMA, fronthaul packets arriving from the network interface card are DMA-transferred directly into GPU VRAM. The payload never enters CPU memory. The GPU processes data where it already resides, and only compact processing results are returned to the host. This transforms the GPU from a device that receives work into the location where work naturally begins.
Inline GPU Architecture in OCUDU
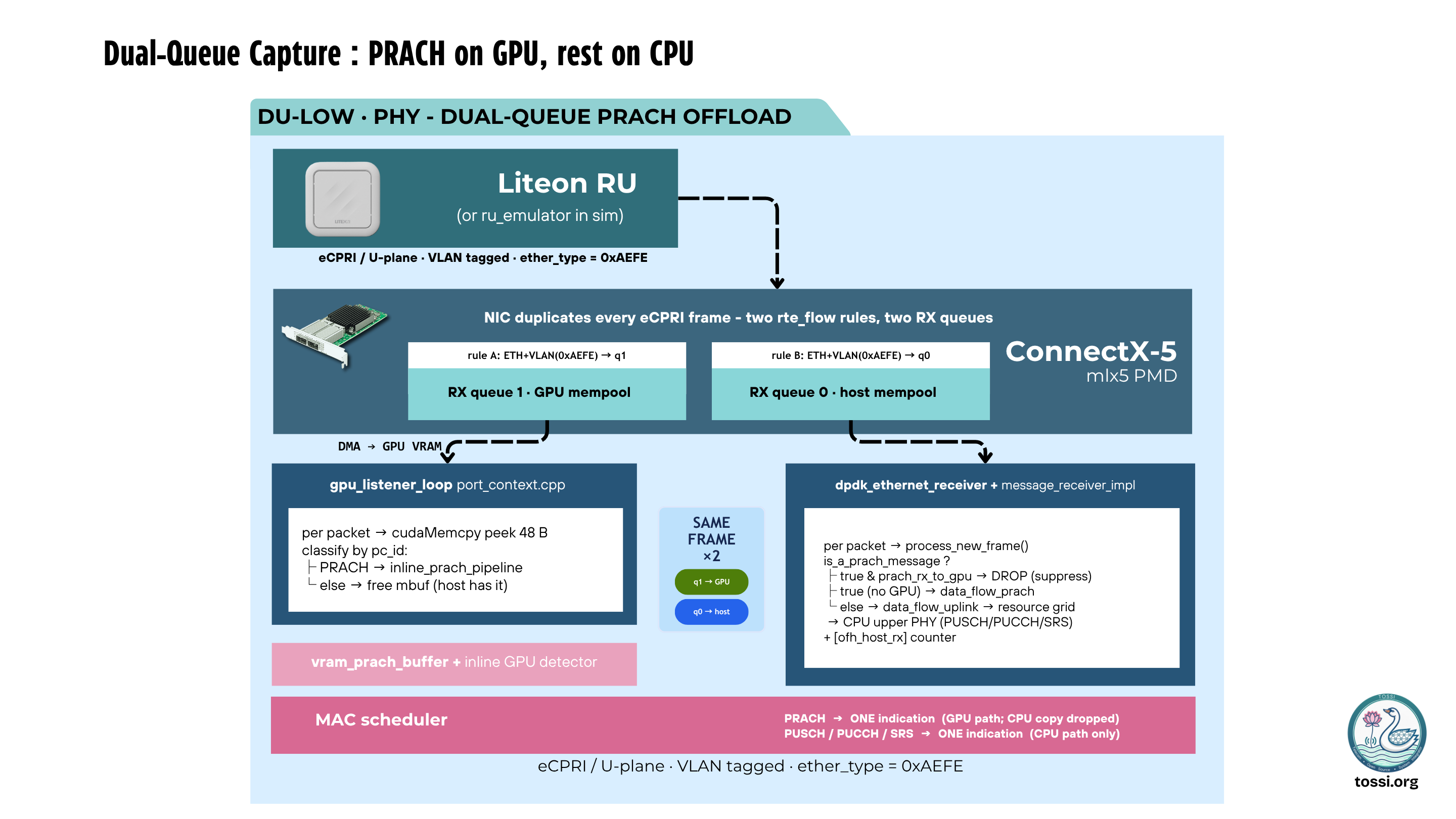
OCUDU now introduces a dedicated accelerated data path alongside the existing CPU processing pipeline. PRACH and SRS packets are delivered directly into GPU memory. A lightweight listener thread examines packet headers and dispatches workloads to the appropriate acceleration pipeline. The payload itself remains entirely resident on the GPU throughout processing.
Key characteristics of the architecture include:
- Direct NIC-to-GPU data delivery using GPUDirect RDMA
- Zero host-memory copies for accelerated workloads
- GPU-resident radio sample processing
- Selective acceleration through configuration
- Full backward compatibility with existing CPU-based deployments
This enables operators and developers to adopt GPU acceleration incrementally while preserving deployment flexibility.
Inline PRACH Detection
PRACH represents the first interaction between a user equipment (UE) and the network. Detection must occur within strict timing constraints while maintaining high reliability under varying radio conditions.
The inline PRACH pipeline executes entirely on the GPU:
- BFP9 decompression
- Resource extraction
- Symbol accumulation
- Zadoff-Chu correlation
- Batched cuFFT IDFT
- Non-coherent combining
- GLRT detection
The CUDA Graph infrastructure introduced in previous releases remains intact. The difference is that samples now originate directly from GPU memory rather than arriving through a host-to-device copy, removing an entire stage from the processing chain.
| Metric | Inline GPU | CPU |
|---|---|---|
| Mean Latency | 106.1 µs | 351.6 µs |
| Detections | 11,350 | 11,350 |
The inline GPU path reduces average PRACH detection latency by approximately 70%, delivering more than 3× acceleration while maintaining identical detection outcomes.
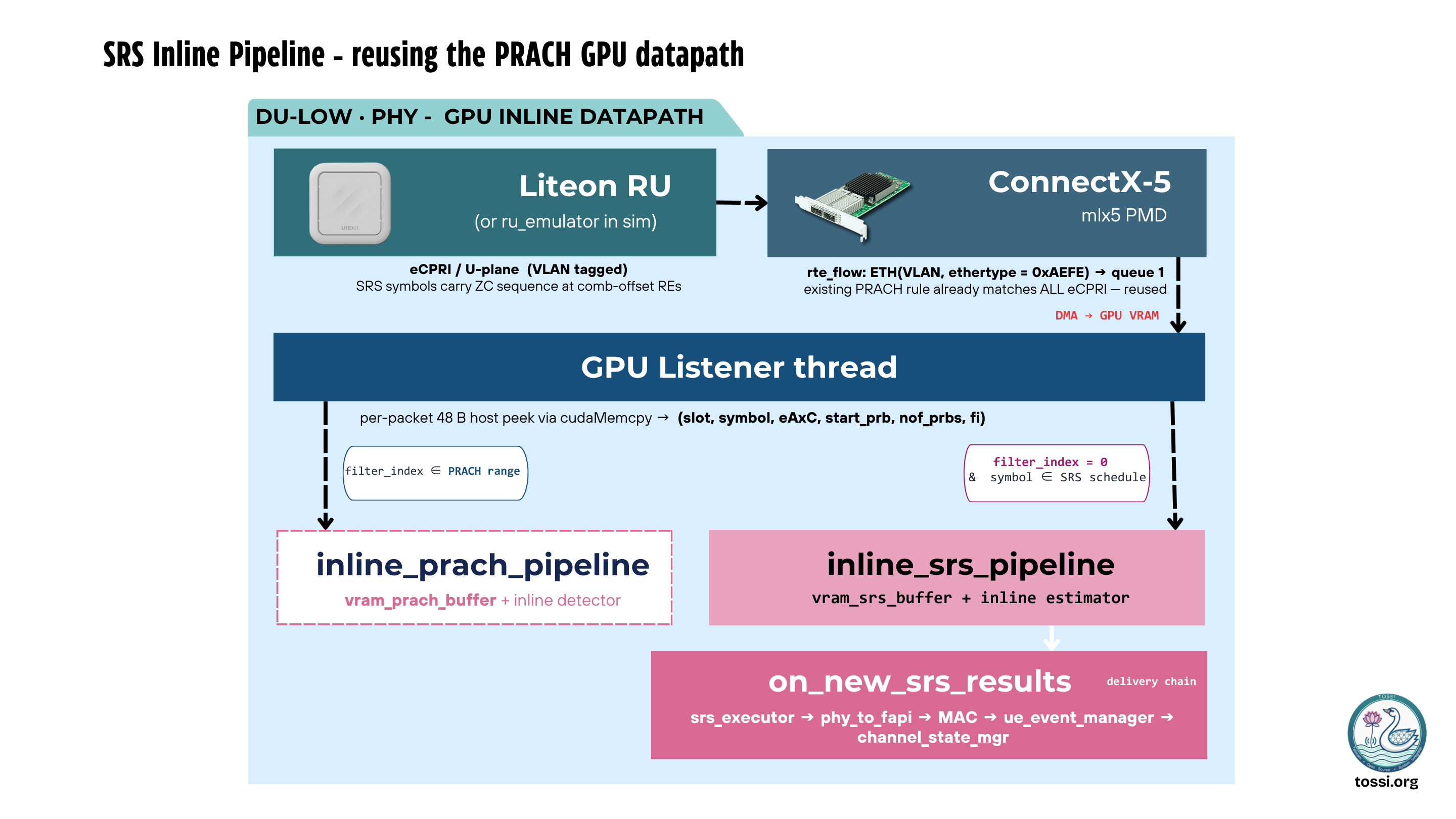
Inline SRS Channel Estimation
SRS processing presents a different challenge. Unlike PRACH, SRS shares uplink resources with user traffic and requires coordination with MAC scheduling information. The OCUDU GPU pipeline performs:
- Least-squares channel estimation
- Reference sequence correlation
- Timing advance estimation
- Phase compensation
- Noise variance calculation
- Wideband channel coefficient generation
Generated channel estimates are published through lock-free interfaces and combined with MAC-layer context before being consumed by higher PHY functions. As user density increases, batched CUDA Graph execution allows many SRS occasions to be processed through a single graph replay, significantly reducing per-user processing overhead.
For a 64-PRB allocation:
| Number of UEs | CPU Cost | GPU Cost |
|---|---|---|
| 1 | 13.5 µs | 44.1 µs |
| 16 | 13.5 µs | 2.7 µs |
| 64 | 13.5 µs | 0.84 µs |
| 256 | 13.5 µs | 0.59 µs |
At low user counts, CPU execution remains competitive. As network load increases, GPU batching dramatically improves efficiency. At higher densities, the GPU achieves more than 20× acceleration while remaining comfortably within the 500 µs slot budget.
Why This Matters Beyond PRACH and SRS
The significance of this work extends beyond PRACH and SRS. Inline GPU processing fundamentally changes where radio data lives. Once uplink samples arrive directly into GPU memory, additional processing stages can operate on the same data without introducing new movement costs.
This enables a future where:
- Channel estimation runs on GPUs
- Neural receivers operate directly on radio samples
- Beamforming algorithms leverage AI accelerators
- Learned PHY components integrate seamlessly into existing stacks
The challenge shifts from moving data to applying intelligence.
Roadmap
Inline GPU processing provides the foundation AI-RAN requires: an architecture capable of delivering radio data to accelerators efficiently, consistently, and at scale.
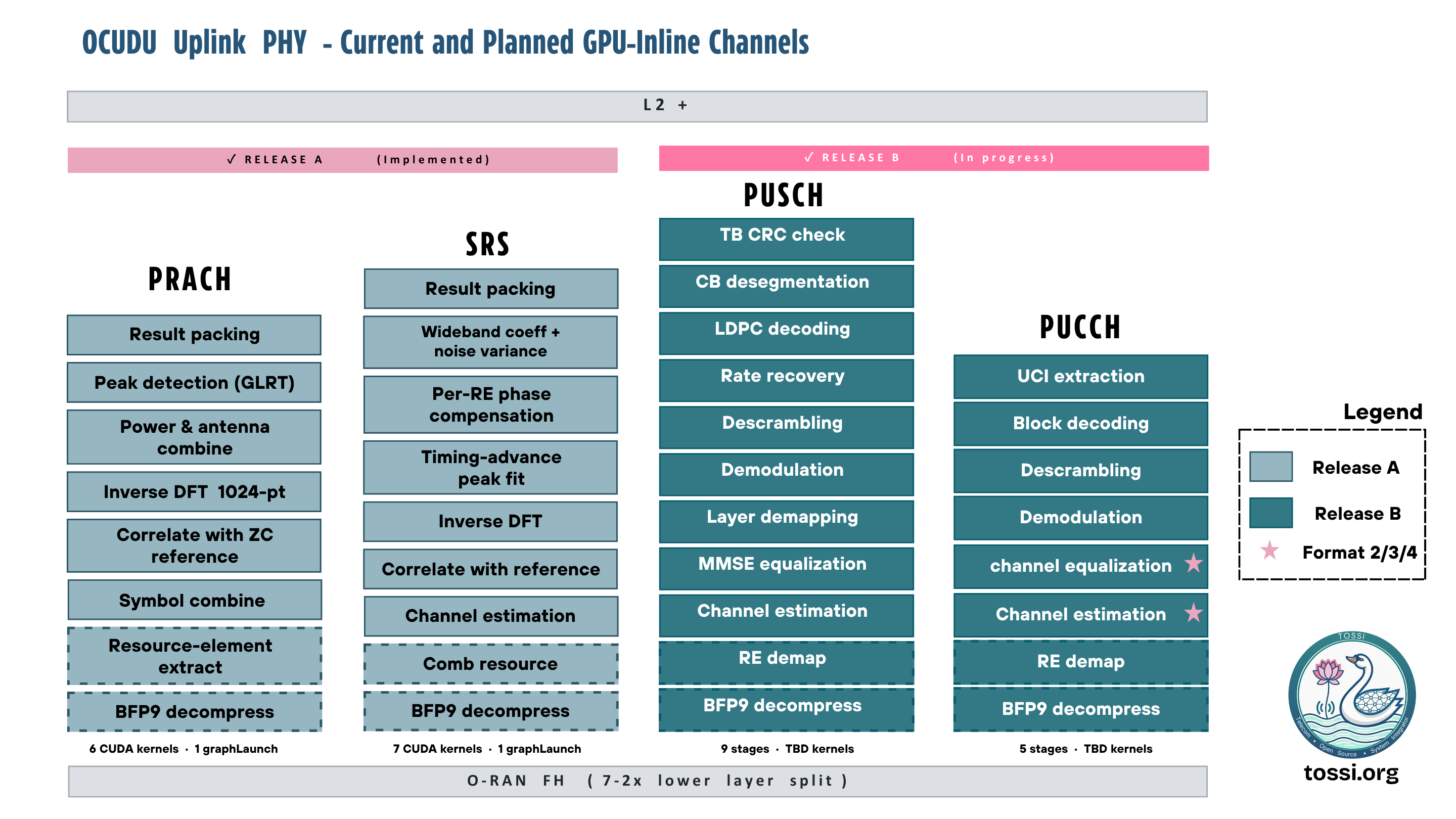
Combined with OCUDU's xFAPI-based vendor-neutral Layer 1 and Layer 2 interoperability framework, future PHY implementations can evolve independently while remaining compatible with existing Layer 2 deployments. The result is a practical pathway toward:
- GPU-native Open RAN deployments
- AI-assisted radio processing
- Heterogeneous compute environments
- Accelerator-aware network architectures
- Open and interoperable AI-RAN ecosystems
This is not simply a performance optimization. It is infrastructure for the next generation of Open RAN innovation. With PRACH and SRS now operating directly on GPU-resident radio samples, the next phase is already underway — extending inline acceleration to additional Layer 1 functions and bringing AI-native radio processing closer to reality.
Availability
Inline GPU acceleration for PRACH and SRS is available today in OCUDU.
- GitHub: OCUDU-RAN — hwacc_gpu_inline branch
- Documentation: Inline GPU PRACH & SRS — TOSSI Docs
At TOSSI, our mission is to bridge open telecom ecosystems while enabling the technologies that will power future mobile networks. From xFAPI interoperability to ACC100 acceleration and now inline GPU processing, each milestone contributes to a common objective: building an open, modular, and accelerator-aware foundation for AI-RAN. The future of AI-RAN starts with the data path, and that journey continues with OCUDU.